Karpathy's Autoresearch Is Two Theses Running in a Loop
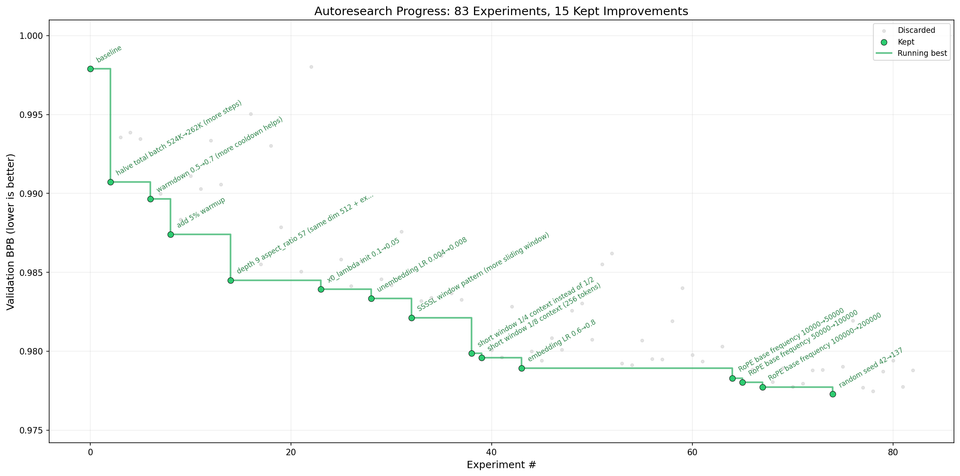
Karpathy left an AI agent running overnight. It executed 83 experiments on a single GPU, each one modifying a GPT training setup and measuring whether the result improved. No human reviewed a single iteration. By morning, the model was meaningfully better than where it started.
The project is called autoresearch. The reason it works comes down to verification cost. Checking "did the model improve?" is a single number comparison. That cheapness is what makes the entire loop possible.
I wrote a few weeks ago that cheap verification determines how quickly autonomous AI loops become viable in a domain, and that the same cheapness enables search through solution space at scale. Autoresearch is both ideas running in a single loop, applied to ML research itself.
How Karpathy's Autoresearch Works
The setup is deliberately minimal. Three files:
prepare.pyhandles data preparation and evaluation. Static, never modified.train.pycontains the GPT model, optimizer, and training loop. This is the only file the agent touches.program.mdis a human-written instruction set that guides the agent's strategy.
The loop: an AI agent reads program.md, proposes a modification to train.py, runs a five-minute training experiment, and measures the result against a single metric (validation bits-per-byte, or val_bpb). If val_bpb improves, the change is kept. If not, it's discarded. The agent then proposes the next modification.
Five minutes per experiment, roughly twelve per hour, all evaluated against the same deterministic benchmark.
The program.md Pattern
The program.md file lays out research strategy: what to try, what constraints to respect, what direction to explore. The agent handles execution, iterating through modifications, running experiments, and filtering results. The human provides the judgment calls ("try architectural changes before optimizer tweaks"). The agent provides the throughput.
Karpathy didn't design a complex orchestration system. He wrote a markdown file describing what he wanted the agent to explore, and the cheap verification loop handled the rest. The human sets direction. The agent runs experiments.
Cheap Verification Does Two Things at Once
The entire system depends on a single property: checking whether a modification improved the model is trivially cheap. Run training for five minutes. Read a number. Compare it to the previous number. Five minutes of compute to generate a result, instant to check it.
The agent doesn't need a human to evaluate its work because the evaluation function is mechanical. If val_bpb went down, the modification was good. If not, revert and try again. Remove cheap verification and the loop collapses. You'd be back to the standard ML research workflow: propose, run, analyze, discuss, decide. Weeks per iteration instead of minutes.
The same cheapness also enables search at scale. The agent isn't trying to get it right on the first attempt. It's running a search: propose modifications, evaluate them against a cheap metric, keep the improvements that survive. Over a hundred iterations overnight, the system explores regions of the design space that a human researcher, limited to a few experiments per day, would never reach.
This is the same pattern behind DeepMind's AlphaCode and FunSearch. AlphaCode generates millions of candidate programs and filters them through test cases. FunSearch uses LLMs to discover new mathematical constructions through combinatorial search. In both cases, the system generates far more candidates than a human would, and verification (running tests, checking proofs) is cheap enough to evaluate them all.
Autoresearch applies the same pattern to the research process itself. The non-determinism that makes verification necessary in the first place becomes the engine for exploring solution space. Generate many candidates, verify cheaply, keep the best. The agent's "mistakes" aren't wasted compute. They're search.
Where Autoresearch Breaks (and Why That's the Point)
Karpathy scoped the system to one file, one metric, one GPU. No distributed training, no complex configs. The README is explicit about the simplicity.
These constraints are deliberate. Each one keeps verification cheap:
- One file means the agent's modifications are bounded. No multi-file refactors where side effects are hard to trace.
- One metric means evaluation is a scalar comparison. No multi-objective tradeoffs that require human judgment.
- One GPU with a fixed five-minute budget means experiments are reproducible and comparable. No infrastructure variability.
Relax any of these and the verification cost rises. Add a second metric and the agent needs to weigh tradeoffs. Allow modifications across multiple files and the search space explodes while failure modes get harder to diagnose. Move to distributed training and you introduce infrastructure variance that clouds the signal.
The boundary of the system is the boundary of cheap verification.
Where This Pattern Points
Karpathy built autoresearch as a proof of concept. But the pattern it demonstrates shows up in other places.
Code has compilers and tests. ML training has loss metrics. Financial models have backtests. Manufacturing has automated quality inspection. Each of these has a verification function that's mechanical, fast, and reliable. Those are the domains where autonomous AI loops seem to work.
The domains where autonomous loops struggle (legal reasoning, strategic planning, creative work, medical diagnosis) aren't struggling because AI can't generate good candidates. They're struggling because checking whether a candidate is good still requires expensive human judgment.
The filter I keep applying: can you define a single, mechanical check that tells you "this attempt was better than the last one"? If yes, the autonomous loop becomes viable. If the answer is "it depends" or "a human needs to judge," you're outside the boundary.
What I'm watching: the companies and tools making verification cheap for new domains (legal documents, medical imaging, engineering simulations). That seems like where the next wave actually gets built.